Finding words in maps
This post follows on from an introduction to our OCR hack post.
The starting point for the map group was to see if we could replicate the results of a deep learning OCR recognition tool called Strabo which was developed for use on maps and other visual material by researchers at the University of Southern California Spatial Informatics Laboratory. If we could do this we would then try to see if Strabo could be run across our own sample of historical maps from the Ordnance Survey. Our sample contained a number of counties: Aberdeenshire, Dorset and Lancashire mapped at different scales, viz. 6- and 25-inches-to-the-mile. Since we are interested in extracting map features at scale, it would be very useful to evaluate the way in which text might be recognised and then analysed across a large collection of maps, because text in fact makes up a large proportion of the information contained in those maps.
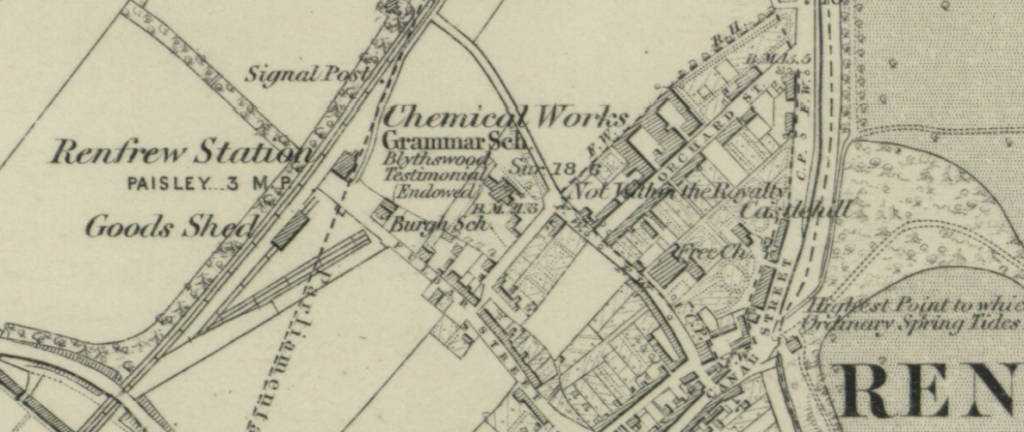
Reproduced with the permission of the National Library of Scotland
This group began by undertaking three parallel tasks: 1) a research engineering task to set up and run Strabo, as documented, on a virtual machine inside the Turing’s cloud computing space; 2) software engineering to modify Strabo to be installed on the Mac with modern libraries and dependencies and 3) a maps interpretation task, of manually selecting a number of map sheets from our sample (of georeferenced maps kindly supplied by the National Library of Scotland) to form a small sub-sample containing a particular set of features for experimentation. The first and second tasks proved fairly time-consuming because of software version and compatibility issues, but was achieved eventually. After a few tweaks we were able to reproduce the sample results provided by the Strabo team. The third task involved searching manually through un-indexed map sheets attempting to find areas of visual interest featuring text which we thought would present different degrees of difficulty for computer vision to extract (including finding matching pairs of maps at different scales for comparison).
Having done this we were able to run the Strabo script on samples of our own choosing. Results were poor to begin with, with a seemingly random variation between images that the script was and was not able correctly to identify as text. Some features which would have seemed intuitively easy, e.g., clear delineated text against a plain background were not being recognised by the script as text, whereas it was creating multiple ‘finds’ against map features such as railway embankments which contained no text at all.
As our digital humanauts began to deconstruct and explore the code further we were able to identify certain parameters under the bonnet which revealed some of the methods Strabo was using. In addition we decided to change the size and shape of the input images we were presenting to the script — making them square and also larger (in terms of pixels rather than absolute size) — this overcame one of the default features of the script; namely, it downsamples image size before processing, making smaller pieces of text effectively invisible to the machine. Using larger image files we were able to increase the success rate with which text was correctly identified on our maps to the point where to the naked eye at least, the script was catching a large proportion of the text on the maps. This led us to wonder if we could potentially use a customised version of such an application at scale with the kind of maps in our sample — maps with their own quirks and visual features, that we hope to understand better as we start working with them.
To conclude, one of the team was able to create a patched version of Strabo to run natively on a Mac which will make it easier for us to continue testing the software further. Once we improve our understanding of how the training procedure interacts with the neural network which underlie Strabo and the OCR element of the package (in this case provided by Tesseract), we can begin to evaluate more systematically its potential for extracting text at scale. If this progresses well, we can move onto the promised land of combining this text with location information which can be gleaned from the GIS data contained in the maps. The ultimate aim here would be to produce both a GIS layer which would make maps text-searchable, and also a large text dataset that can be queried and analysed in its own right. Whether this can be achieved, only time — and further research — will tell.
Latest posts from us







