First crowdsourced datasets available
Thanks to all the online volunteers who contributed to our first crowdsourcing tasks, we’ve got two results datasets ready for sharing on the British Library’s research repository: https://doi.org/10.23636/1197. (See ‘Why is the Communities Lab asking people to read old news?‘ for some background on this crowdsourcing work.) The datasets are published with an ‘open access’ public domain licence, which means that they can be re-used by anyone for any purpose.
The datasets contain the classifications created as members of the public looked at a selection of articles from 19th century newspapers that mentioned machines and decided if they described an industrial accident. A further task asked participants to transcribe personal, organisational and place names mentioned, and add a brief summary of relevant accidents.
By itself it’s probably not the most useful dataset, but publishing the results from our alpha and beta tasks like this is an important step for the project. For example, it meant we had to work out various internal processes (such as redacting personal information like usernames and IP addresses), confirm copyright and licensing (CC0), convert the records from JSON to the more readable CSV so the file could be opened in common spreadsheet software, and figure out what documentation to provide. Now that we’ve done this once, it’ll be easier to repeat for additional datasets.
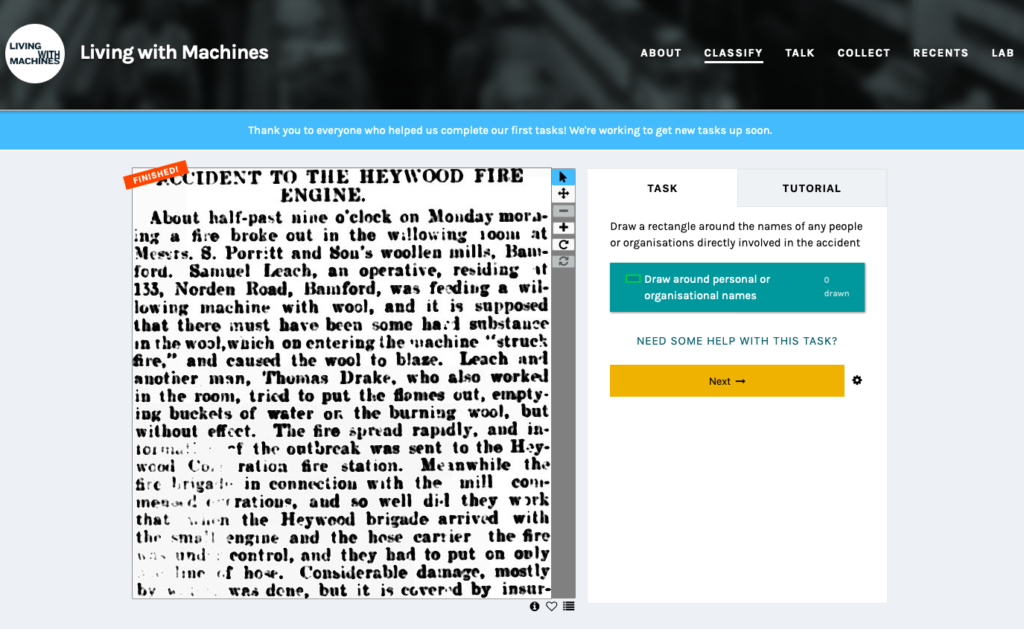
I’ve posted on the ‘Talk’ forum so that our wonderful participants (or indeed anyone with a Zooniverse login) can comment or ask questions: https://www.zooniverse.org/projects/bldigital/living-with-machines/talk/2795/1607419. We’re working on providing access to the underlying OCR text transcription to provide further context for the classifications, and in the meantime we’d love to know whether it’s useful as it currently stands. Is the documentation (on the dataset page or forum post) useful? Is the context of its creation clear from the documentation?
Latest posts from us







