Collecting annotations from British Library staff
Like many projects working with digitised historic materials, the historians and data scientists on the project are facing challenges in working with text produced through Optical Character Recognition (OCR). Some of the project researchers are trying to quantify the impact of OCR quality issues on Natural Language Processing (NLP) tasks. In plain English, these include tasks like labelling parts of a sentence for semantic analysis or identifying the names of people, organisations, places and concepts mentioned in digitised texts.
During the summer we had an open annotation session in which we invited British Library staff members to help with our experiments. We planned four different linguistic annotation tasks (named entity recognition, recognition of machines, entity linking to Wikipedia, and semantic role labeling) on newspaper articles from the nineteenth century.
The annotators were encouraged to try the different tasks, and express all the doubts they encountered. This proved invaluable in redefining the task boundaries in those cases in which they were less clear. This session was also a useful test of our annotation guidelines and see whether our internal documentation was fit for slightly more public consumption.
We also got feedback that one of our annotations ‘machine object’ was sometimes difficult to annotate because the concept was broad. This returns to ongoing discussions within the project about what ‘counts’ as a machine and whether we should focus on historical approaches to this concept or contemporary ones. Ambiguities like these highlight the benefits of carrying out annotations for better understanding your source material and whether your proposed downstream computational tasks match this source material.
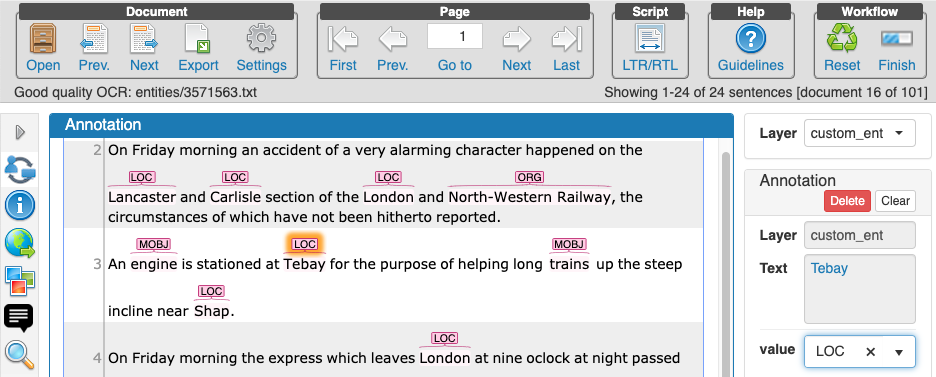
Feedback on inception
A side benefit of hosting the session is that it gave us the opportunity to test out or chosen annotation tool ‘Inception’ with a largish group of users. Inception is an
After the session was complete we asked for feedback on the tool and the tasks carried out in the session. Most of the feedback agreed that the tool was accessible and fast. There were a few challenges around using the tool for our task. One of the main requests is that it would have been useful to also have the image of the newspaper article available alongside the OCR, particularly for the bad OCR examples. This is not surprising given the difficulty of reading the examples with bad OCR.
We hope to explore host more sessions focused on annotation of text soon. We are also keen to branch out into annotations focused on visual material which will help build on work done as part of the Space and Time Lab.
Latest posts from us







