The impact of OCR on downstream Natural Language Processing tasks (tl;dr)
In this blog post, we give a summary of a recent paper written by project members on the impact of OCR quality. The paper can currently be found on the ICAART 2020 website.
As we’ve discussed in previous blog posts, OCR is a big deal for Living with Machines. OCR (optical character recognition) is the way in which images are turned into machine-readable text. Most of the text we’re working with will have been produced through OCR software.
OCR is not a perfect process, particularly for historical materials. This means that much of the text we’re working with has some level of OCR error in them. One proposed solution is to try and correct the errors another to rerun more modern OCR software with the hope of improving the accuracy. Both of these options require significant effort and might not be possible if you don’t have access to the original images (often researchers only have access to the OCR version of documents). Before trying to improve OCR it’s also worth establishing what impact it has for the things we want to do. There has been some great previous work on this including e.g. 1, 2, 3. We built on this work by assessing the impact of OCR quality on a number of tasks. Full details of the approach can be found in the paper.
In this blog post, we’ll just give the tl;dr (too long; didn’t read) summary of our results.
Assessing OCR quality
One option for assessing OCR quality given is the metadata for a digitised item. This is often expressed as either a rating or a score, see below:

There are some problems with this though:
- it’s not always clear how these scores are generated by the software.
- The scores across different software might not be consistent with each other
- Different versions of the software are difficult to compare
Perhaps the biggest issue is that this internal metric doesn’t tell you much about what you can do with that OCR’d text i.e. is it ‘good’ in terms of human readability, or for using to extract named entities etc. We, therefore, want to see what impact there is ‘downstream’ for specific tasks we may want to do. Particularly those done ‘at scale’ where it’s not possible to manually verify your results. We focus on a range of Natural Language Processing (NLP) tasks which are relevant both to our project and the broader digital humanities/digital history fields.
The impact of OCR quality on downstream tasks
In our paper, we compare the performance of various tools and methods on newspaper text which includes both human corrected and OCR generated text of varying quality. See the paper for a fuller explanation of this dataset.
Linguistic Processing Tasks
Linguistic processing involves a number of tasks which may either be used directly or be done as part of a pipeline before using other methods. We consider a couple of key tasks.
Sentence splitting
Sentence splitting is the task of splitting text into sentences. This is usually considered a solved task and isn’t something that requires much thought. Turns out OCR errors mess up the accuracy quite a bit.

Named Entity Recognition
Named entity recognition (NER) can be helpful for finding important information in unstructured text. Entities include; people, locations, organizations, dates etc.
Entities can be used to help information retrieval. Queries to a library catalogue often contain entities i.e. ‘Coventry AND Triumph’ if you are interested in the Triumph bike manufacturer in Coventry.
NER is an active area of research in which you could still win the best paper award at CoNLL (a big NLP conference) or stir up a minor twitterstorm if you improve the accuracy of NER on a benchmark dataset. For this task, we assess the performance of SpaCy, a python library with a good balance between speed, accuracy and usability for many NLP tasks.
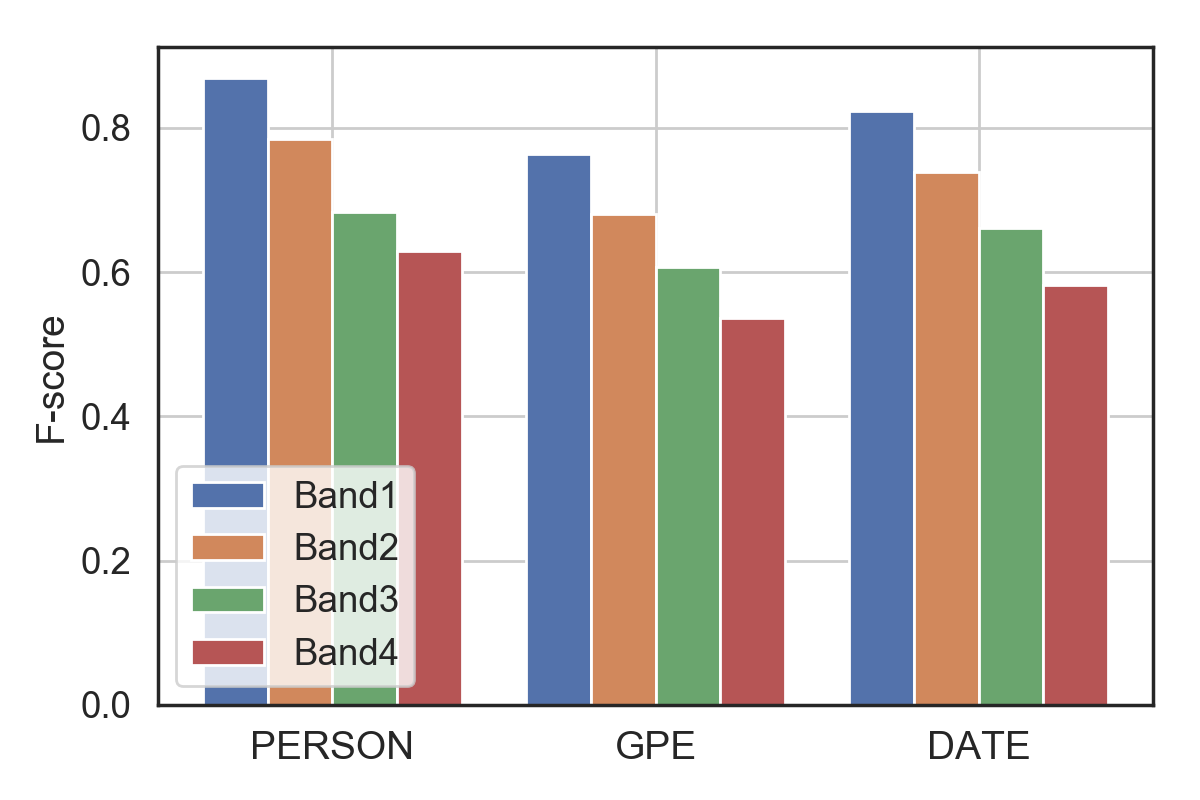
Again we can see that as the OCR quality decreases (band 1 is the best, band four the worst). We can also see that for some entities the drop off in accuracy is steeper. For dates, we can expect that minor errors in the OCR can have a big impact on the ability for them to be detected, whilst person names might be more robust since names can have some errors and still ‘look’ like names to the SpaCy NER model.
Information retrieval
Information retrieval is very important for researchers working with digital collections. Information retrieval or ‘searching’ is often the first step in finding relevant materials whether digital or not. In a library setting information retrieval systems may work purely on metadata, but can also draw on text produced from OCR to generate search results. For this assessment, we used ‘ElasticSearch’ an open-source tool used for searching unstructured and structured data.
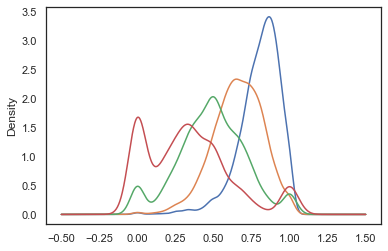
Here we find that compared to the human corrected text we get different results for OCR’d text. As the OCR quality decreases the difference of the results compared to the human corrected text increases. This means that for collections of OCR’d text when the OCR gets worse you can expect different results to if that text was correct. We can’t necessarily say that the results are ‘worse’ but we would at the least want to be careful about making claims about a corpus based on search results if the OCR quality of that corpus is variable.
Sometimes search results are used to plot trends over time. If conclusions are drawn from these counts, it’s important to be aware of the potential that these counts may reflect differences in OCR quality, rather than actual differences in the underlying corpus.
Topic models
Topic models include a variety of methods for generating topics in an unsupervised way from texts. Topic models can be used to cluster similar documents based on topics without having to explicitly define what those topics are. This not only makes it useful for information management but can also be used for research on a corpus itself. Since these topics are not predefined it can help researchers explore a corpus without imposing existing categorisations onto the collection.
The downside of topic models, which have been explored elsewhere, is that the topics can be difficult to interpret. What is returned from a topic model is a number of topics – defined when you run the model and the top texts associated with this topic. Sometimes it may be very obvious that a topic is about ‘sport’ or ‘weather’ but for other topics, it’s less clear. What happens when we throw OCR into the mix? Again we find that the topics produced by corrected human text and the OCR differ. See below for an example:
Human h_0 [('council', 0.00952415),
('state', 0.007095055),
('meeting', 0.0070396387),
('government', 0.006395518),
('committee', 0.0061474955),
('report', 0.005656868),
('new', 0.0048953076),
('present', 0.004818016),
('member', 0.004605099),
('matter', 0.004535686)]
OCR o_1 [('work', 0.006112786),
('council', 0.0045690676),
('government', 0.004097321),
('state', 0.0039760116),
('present', 0.0039747395),
('meeting', 0.003900536),
('aro', 0.0037356666),
('havo', 0.0035805195),
('hold', 0.003366531),
('man', 0.003353959)]
# KL divergence 0.061855365
# Words in common 360
Though there is some overlap, the results we get from OCR are different from those form human text. These differences will be hard to spot without reference to a baseline. Following on from other papers (‘Quantifying the impact of dirty OCR on historical text analysis: Eighteenth Century Collections Online as a case study’) we recommend relying on topic modelling with OCR’dtexts quality ideally above 90%, or at least above 80%. Whilst models below this threshold will ‘work’ they may differ significantly from those which would have been generated if you had the same corpus without OCR errors.
Language models
We briefly explore the impact of language models in our full paper which we won’t cover here to keep this from becoming too long. We hope to have more to say on this issue in the future!
Latest posts from us







