LwM Digital Residency: Accessing and Using Historical Newspaper Data
My Living with Machines Digital Residency, which I carried out between May and July 2023, allowed me to update and publish an online guide to accessing and analysing newspaper data. The goal of the book is to make available an end-to-end set of instructions and tutorials which would allow researchers, with a variety of skill sets and backgrounds, to take advantage of the digitised newspaper data now freely available from the Living with Machines project.
Digitised newspaper data is a hugely valuable source of historical information, particularly for mining at scale. The Living with Machines project itself is a perfect example of one which has used newspaper data as a key source from its very beginning. Other researchers have used newspaper data for everything from mapping political meetings, to finding Victorian jokes, to tracing global information networks.
Newspaper data is appealing to work with because it is highly contextualised with times and dates, it records daily events, and is often a voice of the non-elite. It can offer a window into the everyday life, political thought, and language of the past. The datasets are potentially huge, with many terabytes of data already digitised, larger than even the largest book collections. Because of this large volume of data, it is particularly suitable for computational analyses at scale.
The book seemed timely because, thanks to the Living with Machines project (and another internal project in the British Library called Heritage Made Digital), data from parts of the UK’s national newspaper collection are for the first time available online, free for anyone to use in any way they wish. A total of 57 titles (at time of writing) are available on the Shared Research Repository.
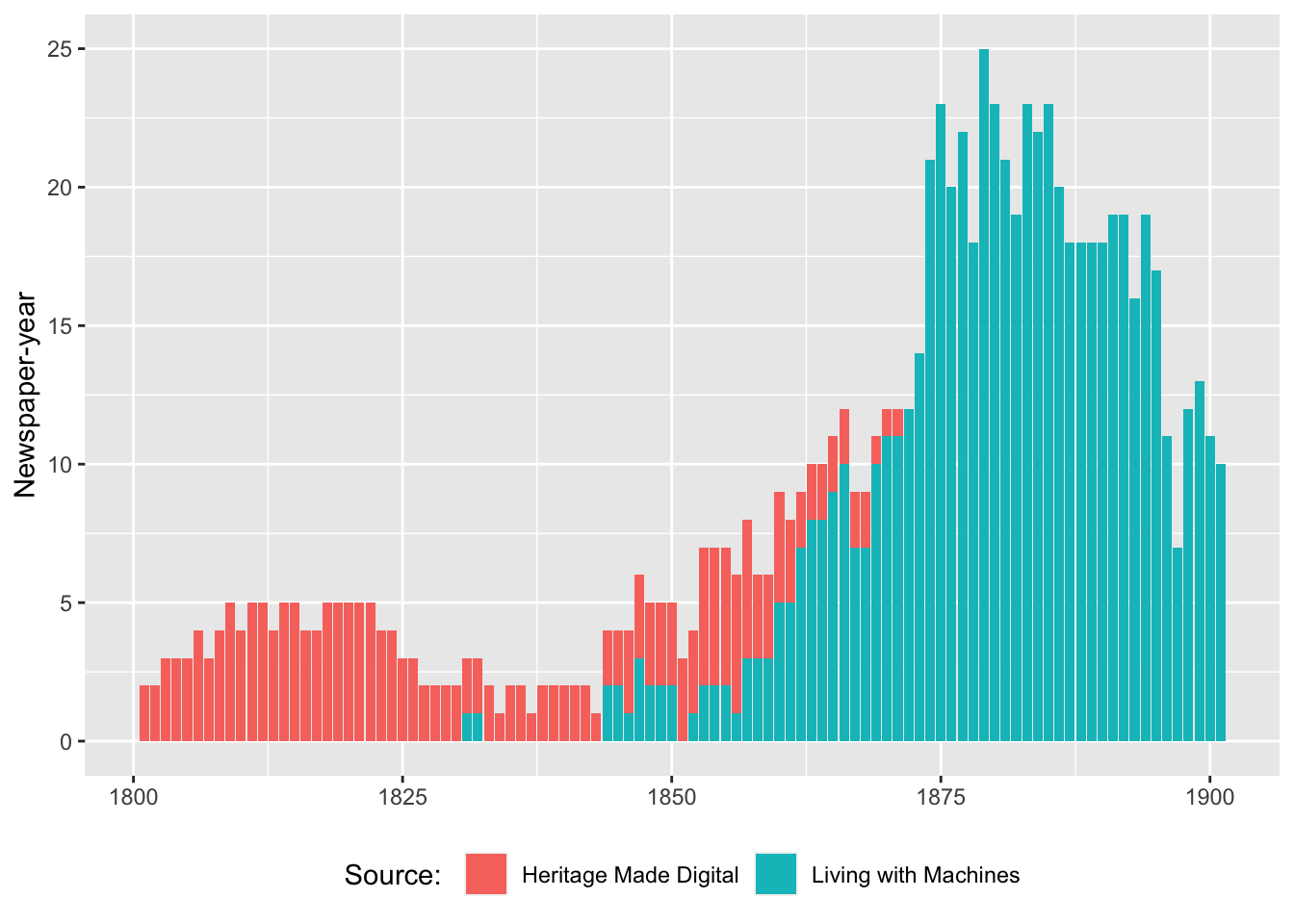
However, working with this data can be quite daunting if you’re new to it. The text is stored in a complicated format called METS/ALTO, and it can be difficult to understand what newspapers are available, where they have come from, and whether they are representative of anything. The aim of my book was to answer some of these questions, and hopefully make it easier for some to access and work with this data.
The result from my residency is a fifteen-chapter book, which covers many aspects of accessing and analysing newspaper data from the UK, written with a beginner in mind. The book is divided into two sections. The first looks at sources, explaining a little about the history of the UK’s digitised newspaper collection, what is available to researchers, and how it can be accessed. The second section is a set of tutorials, which guide a user from downloading titles from the repository, to extracting the text from them, and running a range of analyses. These analyses run from basic (counting word frequencies) to creating your own machine learning model to detect advertisements.
The tutorials are written in R, an open-source and general-purpose coding language. The book itself uses a publishing format called Quarto. It’s essentially a HTML website which allows images, interactive javascript, and code to be embedded within it.
To carry out this project, I used the digitised newspapers from the Living with Machines project as the basis for the instructions and tutorials on downloading and analysing newspaper data. The data in these files were used as the basis for a range of coding topics such as text mining, machine learning, and topic modelling. Doing so meant that the results of the tutorials reflect ‘real-world’ newspaper data research, rather than using modern data or pre-processed files.
The tutorials are meant to provide users with all the information necessary to do analysis on British Library newspapers. As much as I could, the specific challenges of the newspapers, such as the OCR issues, are taken into account. While the amount of data provided is still fairly small, the lessons will hopefully work as a teaching aid, or as a ‘dry-run’ for researchers who would like to try out methods before requesting a larger newspaper dataset on which to try it.
In making this book, my wider goal was to increase the knowledge and awareness of newspaper data and its value for students and researchers of history, linguistics, literature and other disciplines. Perhaps presenting the data in this way may work to stimulate the dialogue around newspaper data accessibility: by demonstrating that even news datasets of this relatively small size are valuable resources in their own right, it may encourage institutions and projects to more freely share their data outputs with as unrestricted a licence agreement as possible.
I hope the book itself will be of use to a range of students and researchers who otherwise do not have the resources, connections, or knowledge to navigate the complexities of commercial agreements and technical file specifications. This, to me, would be the most valuable outcome of this residency and I would like to thank the Living with Machines project, along with the Alan Turing Institute and the British Library, for the opportunity to carry it out.
A big advantage of a self-published book such as this is that it can easily be updated. If you spot any errors, would like to give me feedback or have requests, or just would like to tell me how you used the book, I would be delighted to hear from you. You can email me at y.c.ryan@hum.leidenuniv.nl, or post an issue on the book’s Github repository.
Latest posts from us







