What could be the digital humanities' Hugging Face?
🤗
Giovanni Colavizza and Kaspar Beelen asked digital humanities (DH) researchers which computational resources would (if available) accelerate their research in the years to come.
We called this unicorn “DH’s HuggingFace” in reference to a code library in Python. The Hugging Face library recently boosted various forms of computational research by greatly facilitating the process of working with complex and large deep learning models. In other words, is there a single tool that would boost DH work?
Many researchers in DH—whether they apply topic modelling, word2vec or other algorithms— rely on such code libraries. Many papers and insights wouldn’t have existed (or at least would have required more effort) without the convenient interfaces provided by packages such as Gensim, SpaCy or PyTorch.
Given that code libraries have the potential to empower innovative research, we asked our colleagues what functionalities they would like to see implemented in the near future. Here is what they told us.
Demographics
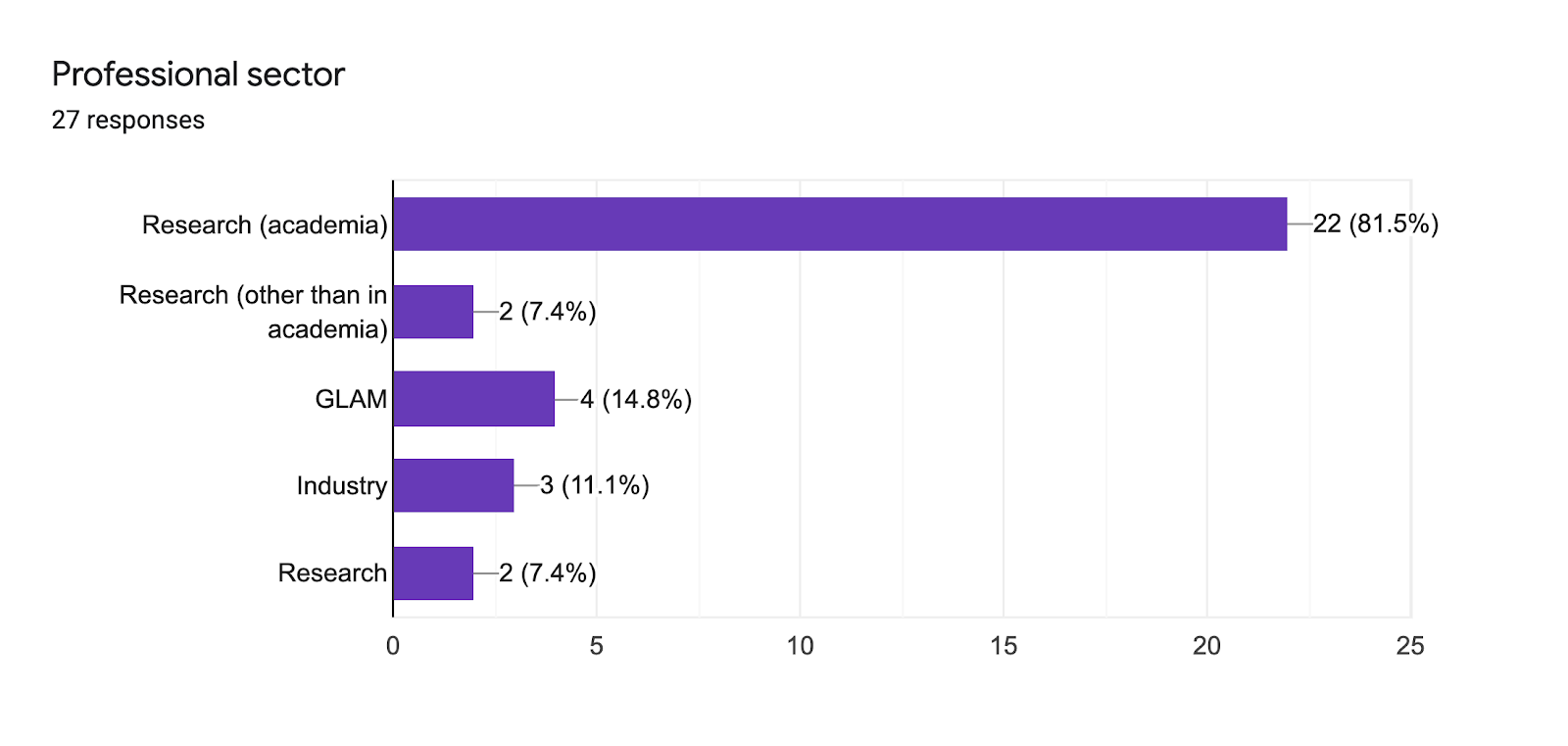
Before picking their brains for moonshot ideas, we asked our respondents to tell us a bit more about their background and the tools they currently use.
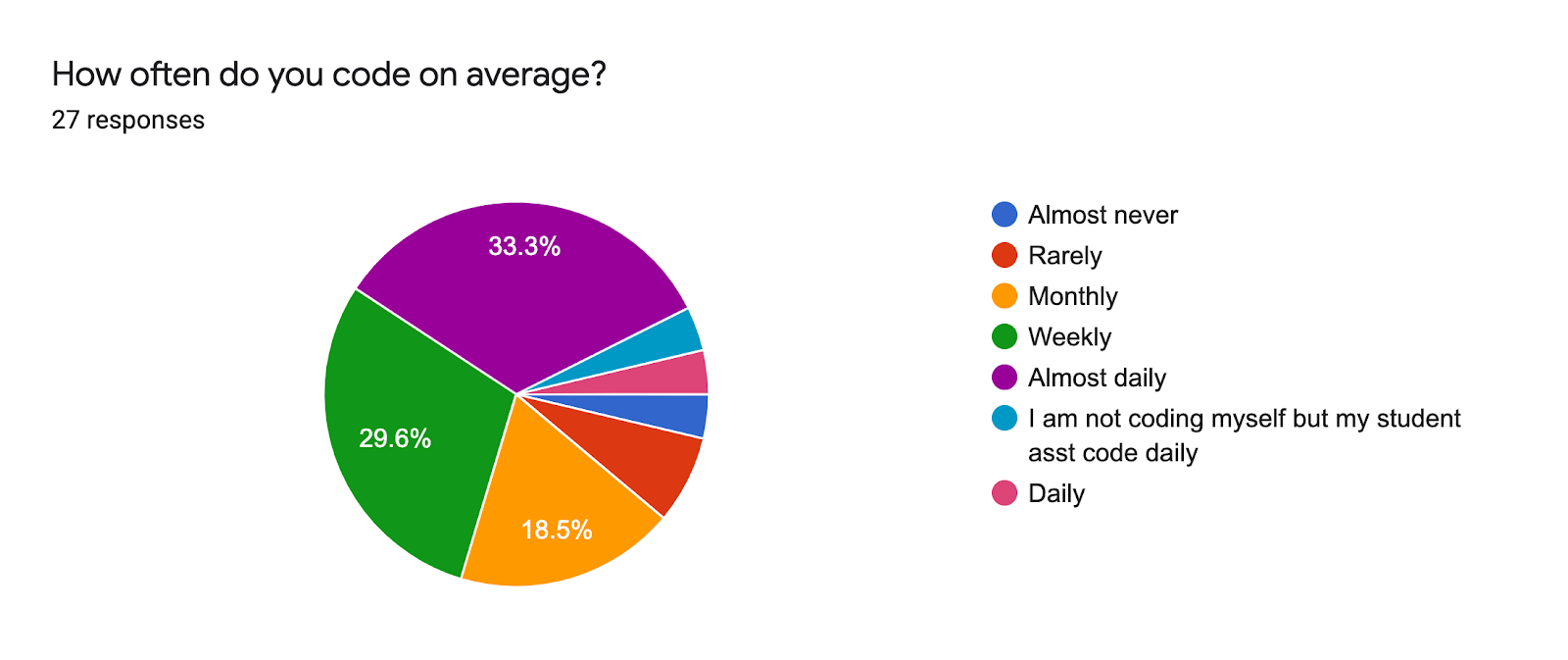
We got 27 responses from a wide variety of professional angles (including galleries, libraries, archives and museums (GLAM) and in Industry) but the majority were active in academic research, most of them using code and data on an almost daily basis.
The survey also underlined the various data types that are currently used in DH: answers included tabular, GIS and (audio)visual data, but text remained the most popular resource.
Most of our respondents currently use the “Python data science stack”—a loosely defined group of packages such as Pandas, Numpy (or Tidyverse for R)—and machine learning libraries (Gensim, Sklearn and PyTorch). Other popular tools handled visualisation (Seaborn, ggplot) or the wrangling of textual data (NLTK, SpaCy).
What is needed: Tools
Turning now from the present to the future, as most of the respondents use code on a daily or weekly basis, we were curious to hear what type of library or functionality they would like to work with in the future.
Many of them expressed a need for more convenient tools to manage annotations. As annotations are a way for encoding “human” knowledge in digital resources, having tools that share, recognize and integrate such enrichments would greatly facilitate research. A more specific (and achievable) wish related to packages that promise to intelligently handle TEI formats (or ALTO/METS-type of documents) similar to how Pandas facilitates reading and exploring data frames. A few packages already provide some relief in this respect, but much remains to be done.
Another recurrent theme in the responses pointed to the historical character and specificity of data in DH. It expressed a need for tools that are better attuned to the historical aspects of the data and, for example, take into account metadata (such as time-stamps) when processing texts. Another example is sentiment mining: the expression of emotions changed over time (and other factors), but no tools currently offer the possibility of attuning models and methods to the historical context and specificities of the sources.
In general, DH would greatly benefit from packages that provide context-sensitive semantic technologies (be it sentiment mining or tracking the contextual change in the use of words). Given that many packages now provide tools for fine-tuning models on specific datasets, this moonshot idea may be achievable, if data and models could be easily exchanged.
In this context, more than one respondent pointed out that the community would benefit from converging on tools for fine-tuning and exchanging machine learning models. This would allow researchers to adapt their computational instruments to their sources and share them with the wider research community. Having tools that not only load and apply models but also expose information on how they were created—and what they were originally intended to do (similar to “model cards”)—is considered as essential in this regard.
Shared Tasks
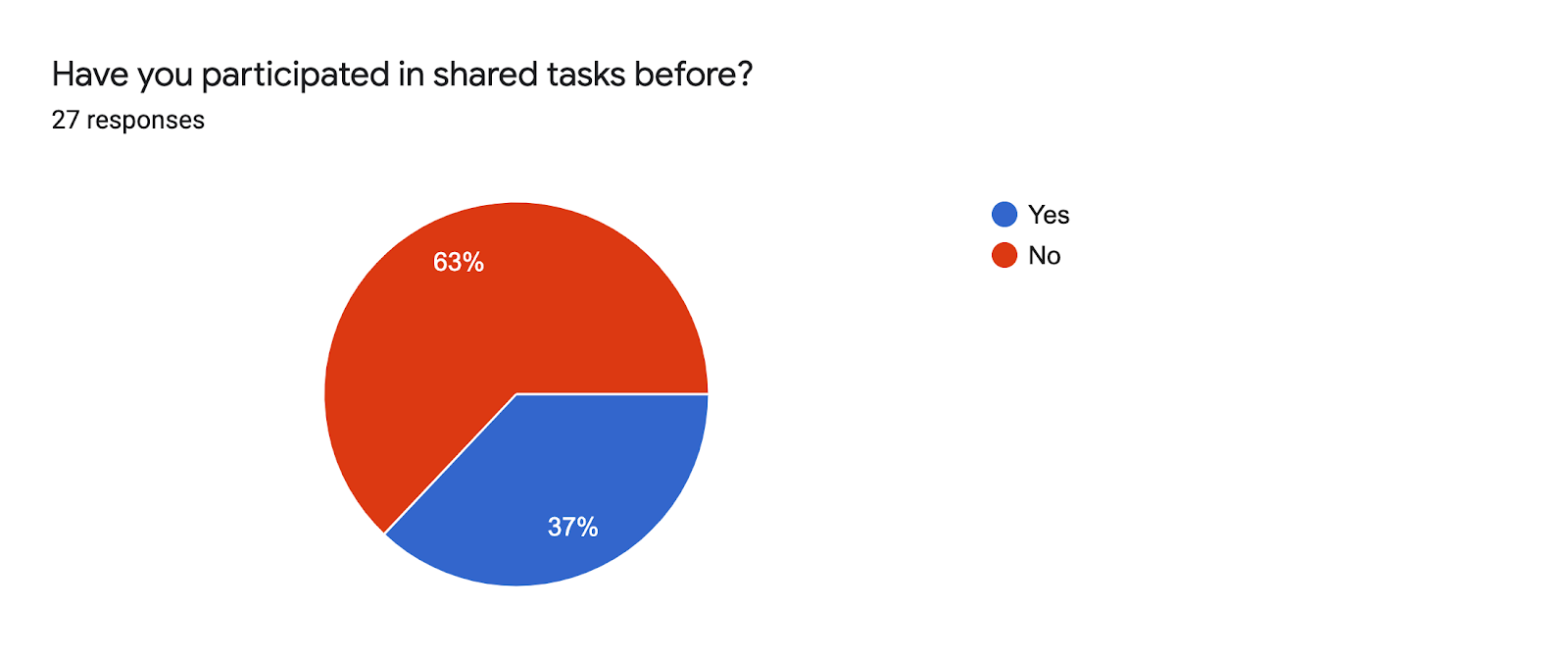
The survey concluded with a few questions on shared tasks, a type of challenge (even competition) in which researchers from many different institutions try to tackle a common problem. These are another approach tackling common challenges and contribute to developing more powerful and refined tools for computational humanities.
Shared tasks are still somewhat novel and while most of the respondents rely on code for their daily work, they have less experience with these types of activities, maybe because DH research hasn’t converged on shared data and tasks to improve its research. As one respondent noted “Shared tasks […] are often a reduction of the problem. […] Within DH the data and the questions can’t really be abstracted to an easy task with ground truth.”
When asked what would make shared tasks more relevant to DH, some of the respondents hinted that instead of working on a common task, DH needs a change in attitude – to shun the protective lone-scholar model of the “traditional” humanities and embrace openness, celebrate collaboration and agree more on shared research practices. Others pointed to the need for shared data, both for research as well as benchmarking.
Conclusion
All in all the survey did not identify a single Hugging Face for DH, but some recurring ideas emerged from the survey, especially the need to streamline workflows and build shared resources. Maybe not code, but more openness and transparency will unlock new research opportunities in the future.
The survey is still open and awaiting your answers! If you’d like to contribute and share your ideas please follow this link: https://t.co/YA7n6eKs3n. If you would like to access the survey data, please get in touch with us.
Latest posts from us







