Digitising newspapers press directories to understand the landscape of historical newspapers
In this blog post, we introduce the digitised newspaper press directories, a dataset central to the Living with Machines project. We first explain the research context and reasons for digitisation. Then we briefly discuss the digitisation process and describe the data.
Of course, the impatient, or busy, reader can skip all of this and download the Press Directory Data and Data Card at https://doi.org/10.23636/pbq5-9k28.

Research context: Understanding the digitised press
The Living with Machines project began with historical newspapers as a vital source to better understand how, during the long nineteenth century, mechanisation changed the everyday life of ordinary people.
But interrogating such an enormous and opaque corpus at scale brings various challenges. We know, for example, that digitised newspapers constitute a small proportion of the historical press as a whole.
To gauge the contours (and biases) of the digitised press, we needed to situate it within what we called ‘the newspaper landscape’, the population or totality of newspapers known to have circulated in the United Kingdom.
Luckily, such a resource exists under the name of ‘Mitchell’s Newspaper Press Directories‘. Published (almost) annually from 1846, Mitchell collected information on the newspaper industry in a systematic fashion, thereby producing small but detailed portraits for each newspaper.

Figure 2 shows an extract of Mitchell’s. The directories organised the newspaper landscape by place of publication.
For each newspaper, Mitchell furthermore recorded the title (of course), when the newspaper was established and the days it was published, as well as the price and its declared political leaning. This was often followed by a description of the paper’s circulation (but please take this with a grain of salt, see the Press Directories Data Card) as well as its audiences and interests
As you can see, these profiles contain a valuable and mostly systematic depiction of the Victorian press. It was our aim to capture this information and make it available to a wide range of researchers in a digital format.
The digitisation process

The task we set ourselves was to convert scanned images to structured data. The image above shows the input and the output of the digitisation process: in goes an image, and out comes a table that captures certain recurrent elements, such as title, price etc.
We received the original scans from the British Library Imaging Studio, which were (in the first instance) converted to text with the ABBYY software. However, as is often the case, modern software does not process historical materials very well – at least not without an adaptation.

The image above points to textual elements that caused problems. We, therefore, set out to build our own digitisation pipeline with a technique called transfer learning. In transfer learning, we adapt large computer vision or language models to a specific domain. By fine-tuning these models on a small set of examples (taken from the press directories) we can ‘teach’ them how to process these specific materials.
We used transfer learning to detect columns, and to improve the OCR.
After converting the images to plain text, we processed the output further, detecting the separate entries and systematically extracting the information contained within them, such as title, politics and price (see below for a more exhaustive overview).
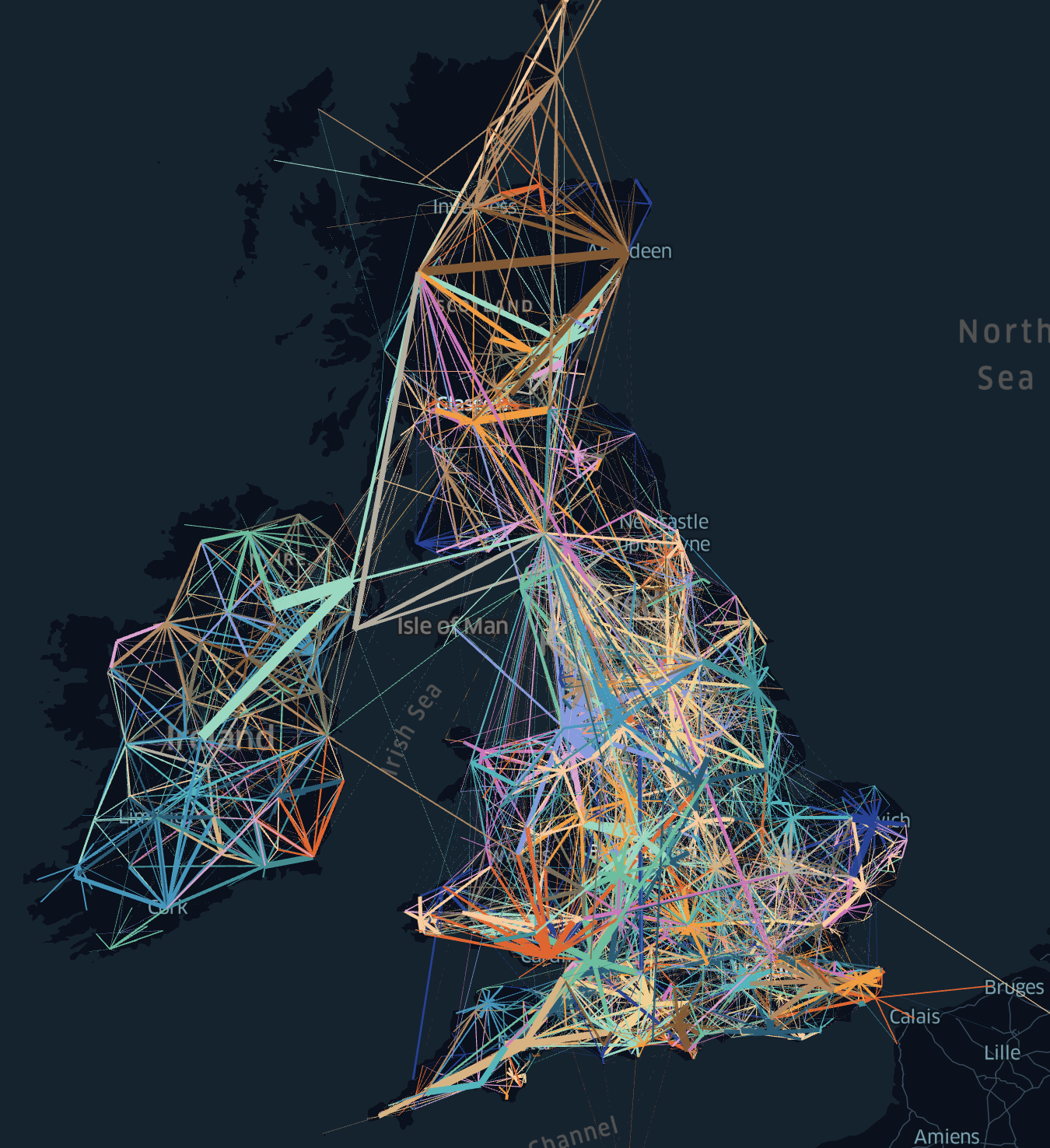
We also collected geographical information, using the project’s tailor-made toponym resolution pipeline T-RES. This enables users to study where newspapers were published and circulated. Each place was linked to Wikidata and associated with geographic coordinates. The above image presents the newspaper landscape as an information network, in which we connect places of publication with circulation.
As Mitchell appears almost annually, repeating entries across editions, newspapers can be traced over time, and you can, for example, analyse changing ownership, price fluctuations, or shifts in political orientation.
Some (cautionary) concluding remarks
But, as the cautious and critical reader might wonder at this point, how reliable is Mitchell as a historical source? The answer to this question is mixed.
The information gathered serves mainly commercial purposes. Mitchell catered to advertisers who wanted to buy up space in newspapers and sell their goods and services to the right audiences.
But even admitting that the press directories were not produced by pure altruism, does this make them unreliable? The answer, we think, is ‘no’, but we do recommend taking information with a grain of salt.
For example, newspapers had an incentive to inflate their circulation (and hence readership). Also, scholars question Mitchell’s definition of newspaper. More importantly, not everything was recorded. Newspapers with a shorter run or certain political interests — such as papers supporting the suffragette movement — were especially unlikely to make it into Mitchell’s.
We also need to emphasise that these data are automatically generated and therefore prone to some errors from the OCR or the parsers used to extract information. We manually corrected the data as far as possible, but it will never be perfect.
Having said that, the directories do provide an incredibly rich and extensive record of the Victorian press, which generations of (media) historians have consulted in the past to find and describe newspaper titles.
With the digitised version, you can now save yourself a trip to the British Library reading room.
More importantly, you can also benefit from the affordances that come from digitisation, such as searching, visualising and analysing the press at scale.
Please let us know what you think! Is this a useful dataset? Can it be improved? If so, how? We are aiming to upload future corrections. Stay tuned.
Latest posts from us







