Directory Enquiries: machine learning to unlock radical historical context, Part Two
This post is about using machine learning to process difficult historical materials for use in research. It is the second in a series, and follows on from this entry on the blog of our sister UKRI-funded project, ‘Congruence Engine’, in which I outlined the motivations for converting historical trade directories into a structure dataset, as well as some of the challenges this involves.
In this post I explain how we approached this challenge at a collaborative workshop hosted at the Turing (as part of the Living with Machines Distributed Conference), which incorporates work by my colleagues Kaspar Beelen, Katie McDonough and Kalle Westerling).
To recap briefly: many historical documents remain out of reach for computational research because their page layout prevents their contents from being correctly machine-readable. Publications using tabular, semi-structured or column-based layout – such as newspapers, reference works and, above all, street, postal and trade directories – create great difficulties for existing off-the-shelf OCR and document analysis systems. And yet, these remain some of the richest and most valuable sources of information for historians.

There is now a growing community of researchers working on new approaches to document analysis across different types of subject domain, that bring elements of computer vision (CV) and machine learning (ML) to bear on this problem together, often using ‘multimodal’ approaches, i.e., by combining visual and textual cues in a mutually beneficial way, to improve the interpretability of both. Multimodal techniques have caught the popular imagination with applications that generate images from text, such as Dall-E and Stable Diffusion. They have also prompted theoretical reflections drawing on humanities-related areas of CV research in which the now familiar ‘distant reading’ of texts has become the ‘distant viewing’ of large sets of images (see recent work by Hiippala, Arnold & Tilton, and Smits & Wevers).


'High-class Machine Tools'. An example of multimodal content from the advertisements section of the same directory. Reproduced with the permission of the University of Leicester Library, Special Collections. (CC-BY-NC). The multi-faceted, heterogenous, text and visual combinations that appear in historical trade directories make them an ideal candidate to test out some of these new methods in CV, as well as providing a new genre of document on which to experiment. For these reasons we convened a workshop at the Turing offices in London, to address this multidisciplinary problem with a team effort, which would require: curatorial and historiographical understanding as well as a combination of research software engineering expertise in machine learning, computer vision, layout analysis, OCR, text manipulation, data wrangling and modelling. Our two objectives were: 1) to ascertain the current state of the art, and 2) to think practically about what researchers would need from a machine-readable collection of trade directories. The answers to these questions would be essential inputs to the design of a pipeline for the creation of such a resource.
After reviewing the historical and technical literature, we wrangled the image and catalogue data created by the University of Leicester Special Collections into a form from which we could begin exploring the material in detail. I was ably assisted in doing this by Kalle Westerling, who was also instrumental in our decision to use the open source LabelStudio platform for annotating our image data.
We know that computational approaches to inferring the structure of documents (such as our Trade Directories) excel at simple tasks of dividing, for example, the body of a text on a given page from the header and footer; or, of finding the position of text columns; however, they struggle to capture the level of nuance involved in more complex page layouts, in which crucial semantic information such as categories and headings are encoded in the placement of text on the page.
While human readers are quickly able to distinguish between types of page within a complex text by reading the visual cues provided by different page layouts, this is not a straightforward task to automate; and yet it is a crucial first step in processing a large collection of documents: you need to know which pages you are looking at before you can begin to analyse their content.
To make our task more feasible and to concentrate on the most immediately interesting data in these directories, we focused only on the ‘trades listing’ sections. To find these, we tested two ways of classifying page types: 1) using a binary classification schema of X or Y (i.e., either ‘trades listing’ or ‘not’) and also 2) using a multi-class schema (defined in conversation among historians) comprising nine different types of page, of which ‘trades listing’ was one. To understand how well an automatic method would work on these tasks, we created some gold-standard data by hand: to train a machine learning classifier but, also, against which we could evaluate our machine-learning predictions.

A schematic diagram illustrating the multiclass approach to classifying page types. We chose LabelStudio as our annotation platform because of its suitability for collaborative data labelling: it has a user-friendly interface, efficient annotation templates, and powerful backend tools. The developers provided us with temporary access to their Enterprise Edition, which allows multiple annotators to work at the same time robustly while allowing us to load images from our own off-site storage. The platform also supports open formats for import, such as JSON, which made it easy to integrate with our existing data structures.

A screenshot from one of our LabelStudio annotation tasksTuring’s Research Engineering Group and Living with Machines project between them committed around ten team members over two days (in addition to those mentioned above: Professor Jon Lawrence, Giorgia Tolfo, Daniel van Strien, Guy Solomon, Ryan Chan and David Salvador Jasin), who were joined by Science Museum researchers Anna-Maria Sichani, Daniel Belteki and Stefania Zardelli Lacedelli. We were also joined by Asa Calow of MadLab, Professor Jon Agar of UCL and the University of Leicester librarian responsible for the directories, William Farrell. All of the above engaged actively in helping co-design and complete various annotation tasks, for which I am extremely grateful.

The importance of in-person collaboration: discussion, annotation and research in action.The process of annotating data can itself be a rewarding and creative part of the research process, in which historians and data scientists develop labels together. Unexpected benefits and insights frequently result from these multidisciplinary translations, as we move from analytical categories to computational tools and back. Creating a list of nine labels might make sense from the point of view of the historian aiming for completeness, but if our main interest is to identify a single page type, this may confound a computer vision algorithm, for which a binary classification may work better.
Thanks to the easy availability of pre-trained CV models (for example on HuggingFace) we were able to annotate sample images while sitting together and discussing difficult edge-cases, and then to fine-tune and test a simple classifier before the end of the workshop. We experimented with two promising models: ‘Donut‘, which is a multimodal ‘DOcumeNt Understanding Transformer’ model (which makes use of text and image on the page); and ‘DiT‘, which is a purely image-based ‘Document Image Transformer’ model.
In an initial experiment on the page identification task using the multi-class approach (using nine classes, mentioned above) a fine-tuned DiT model was able to classify the page correctly 80% of the time, whereas a binary-class approach worked between 98% and 100% of the time. Such impressive early results help guide future planning around how best to annotate data at different stages of the pipeline: in this case, confirming the hunch of our data scientists that a binary approach would be likely to work better for this first task.
A more traditional approach to parsing data is to use patterns detectable within text strings, rather than a cutting-edge method such as computer vision applied at the image level. This relies on there being some OCR text which, in the case of the Leicester collection of trade directories, exists in the form of very coarse plain-text. As a form of baseline comparison, against which we might better be able to evaluate results from ML/CV approaches, we experimented with using Regular Expressions – a highly versatile string matching method – to see how much semantic sense we could extract from the existing OCR text produced by Leicester in the 2000s.
Even very messy OCR retains implicitly structure information which can create discernible patterns.

An example of some very messy OCR text from a trade directory.Even a snippet such as this contains some cues to recovering the original document structure: the word TRADES. indicating a heading, or the commas used to separate names from trades. Capturing such patterns automatically can allow us to introduce a layer of meaning to the text, establishing whether a particular text block involves a list of professions or locations.
Regular expressions involve a simple technique for parsing text, yet are fiendishly complex to write. As an initial experiment we built a rudimentary parser that i) selects pages with trade listings and then ii) counts how often each trade occurs. First we matched page headings, to establish whether they consisted of ‘trades listings’ and then attempted to match subheadings describing the specific trades listed. Because the latter are commonly printed in capitals, this was our cue; and, finally, we counted the number of lines which appeared. Mapping each trade to a line count, for example, in 1914, provides a list such as this.
{'MANUFACTURER.': 87, 'MILLINERS.': 632,
'LODGING HOUSES.': 61, 'HILLARY': 1,
'MACHINE KNITTER.': 1, 'MOTOR': 19, … }
We repeated this procedure over a range of years, producing a table which includes the beginnings of a useful source of information a historian may recognise for studying the changing quantity of trades and occupations e.g., by location over time.
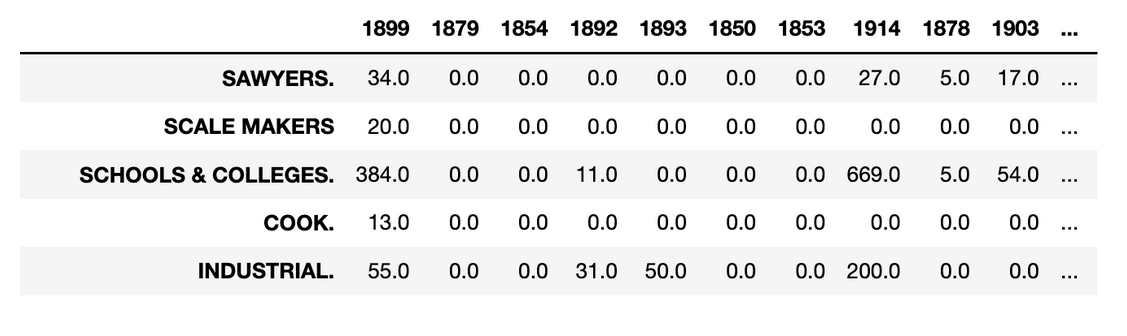
A snippet of a dataframe showing experimental results produced using RegEx (by Kaspar Beelen)There are obvious limitations to such an approach. As well as being laborious, it is not a method that can generalise easily: any divergence in layout or printing practices will cause the parser to fail miserably. Nonetheless, it can prove very useful both as a baseline against which to compare more cutting-edge approaches, but also as a rough-and-ready way for researchers to begin exploring the data.
Collating the many different insights of this workshop – the discussions about annotations, categories of analysis, the annotations themselves, the most appropriate models for the task, the merits of CV approaches versus OCR, among others – has been a complex task which remains ongoing.
Some subsequent experimentation with Federico Nanni points towards the utility of a mixed approach which is modular in nature. It may be simplest to imagine splitting columns first (a relative easy, generic CV task), followed by a multimodal approach to capturing the complex semantics of page layout, building on off-the-shelf OCR models.

A schematic of step two in a future pipelineFor each step in any future pipeline for parsing trade directories, it will be necessary to adapt our methods as the state-of-the-art changes, in what is now a very active field developing across many different subject domains.

A schematic of step three in a future pipelineA pipeline tailored for parsing historical directories specifically, will need to be well-adapted, drawing on expert historical scholarship and drawing on the multidisciplinary advances currently taking place. As computer vision and machine learning allow the completion of ever-more complex feats of information processing, the goal of unlocking these rich treasure troves for historical research comes into view as a realistic prospect. This will be the goal of future work.
If you are interested in this research or have an interest in in trade directories, or similar structured historical documents, please get in touch via email [dwilson AT turing.ac.uk] as we look to build a community of possible users and collaborators in this area.
Latest posts from us







