Press Picker: visualising formats and title name changes in the British Library’s newspaper holdings
One of the challenges in Living with Machines is making sense of collection metadata at scale. This is something we faced making digitisation selections from the British Library’s substantial newspaper collection. We’re directing our digitisation to help redress some of the biases in the existing digital sample. This previous post describes the balancing act between the requirements of a digitisation studio versus those of a research-driven project. Here, I describe how we made digitisation choices under time and resource pressure and the new tool for overviewing the British Library newspaper holdings, Press Picker, we built to help us.
Selection criteria
To make a selection of newspapers to digitise in Living with Machines, there were research-led and practical factors. (Criteria were determined with input from multiple parties: academics—mostly historians—, newspaper collection curators and cataloguers, copyright experts, and conservation experts).
On the research-led side, we were looking for titles published between 1780-1918 from industrial areas underrepresented in the existing digital archive. We preferred titles published weekly over daily, and with longer publication runs, amongst other criteria. (A newspaper ‘title’ here means, for example, The Times or the Blackpool Herald).
But there were also practical factors. As a time-limited project, it was obviously important that digitisation be completed quickly enough for us to use. At the British Library newspapers are stored in hardbound volumes. But some newspapers at the British Library have been microfilmed. Microfilming is where a copy has already been made on a kind of film reel. It’s much quicker to digitise off microfilm and it avoids delays due to conservation. It’s also cheaper, so we prioritised digitising off microfilm.



To complicate matters further, titles sometimes change their name through time. For example, The Athletic Reporter in 1886 becomes The Reporter, which in 1888 becomes The Midland Counties Reporter and General Advertiser, which in 1889 becomes The Reporter and General Advertiser, and so on. Title name changes are pretty common in this collection; we needed a way to make sense of this.
A data-driven approach was helpful for some of these criteria. Narrowing down to undigitised titles overlapping our date range and from six counties (Lancashire, Warwickshire, Yorkshire, Glamorgan, Lanarkshire, and, as a non-industrial control, Dorset) chosen by the historians left about 2,500 titles. Allowing for our budget, our aim was to narrow this down to about 50. How could we make the selection?
Press Picker
Our solution is a custom tool—Press Picker—for overviewing British Library newspaper holdings over time. Press Picker consists of two Jupyter notebooks. The first notebook does data filtering and processing. The second notebook produces an interactive visualisation, which can be used to select titles.
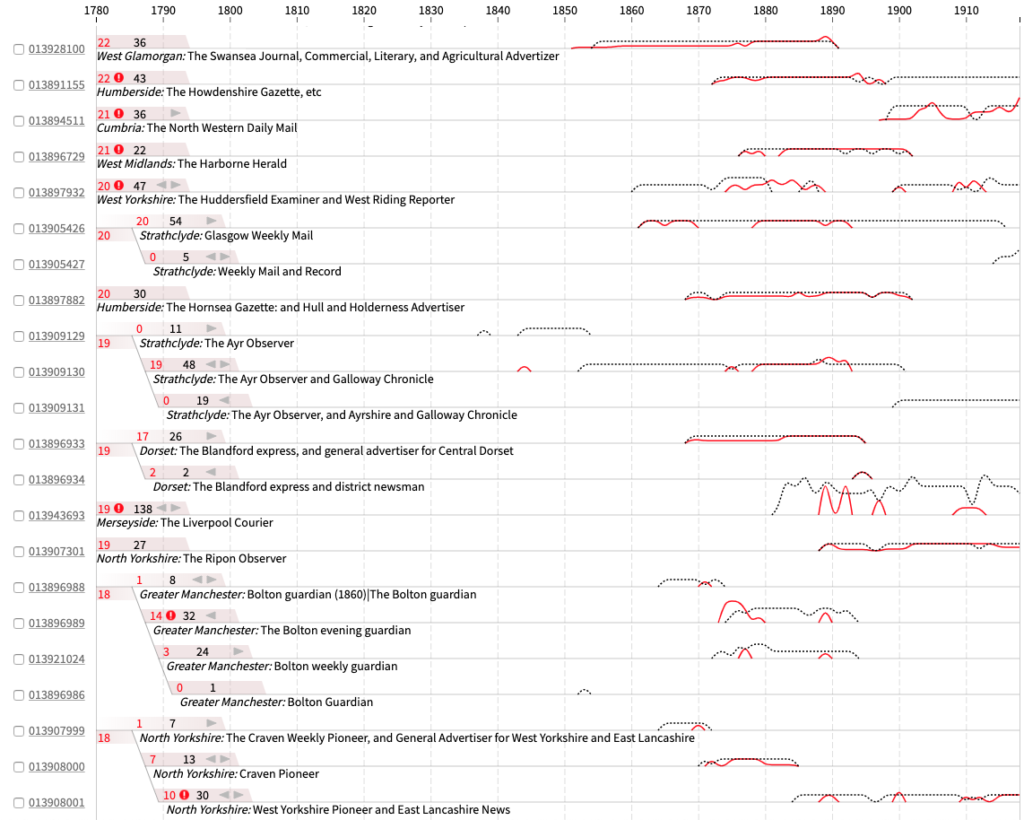
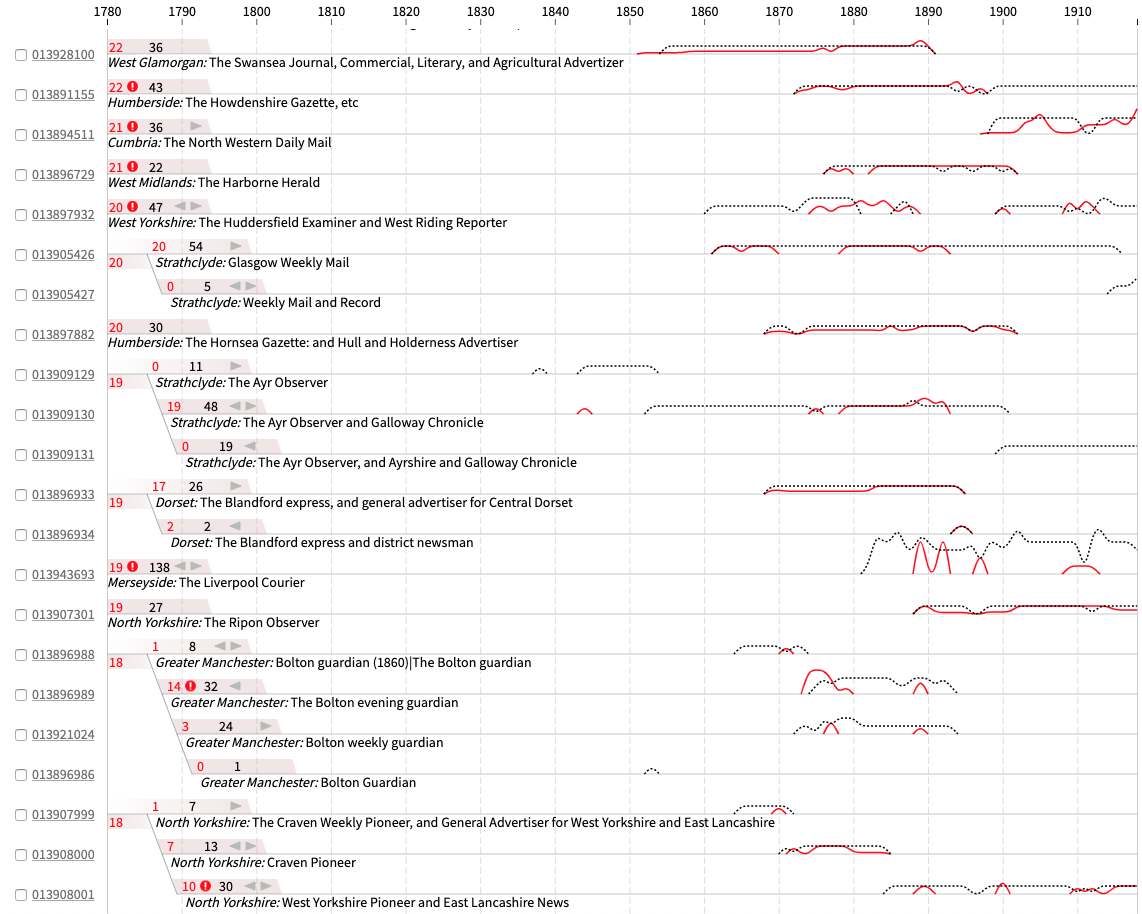
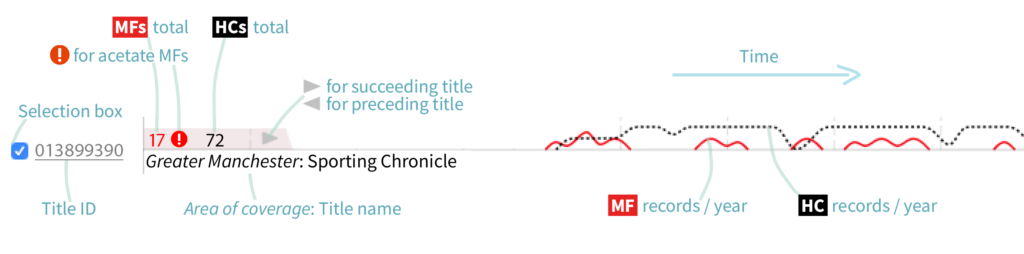
Each title is represented as a small line graph with time running horizontally. There are two lines: the height of the red line is the number of microfilm records per year and black/dashed is hardcopy. Numbers at the left are the microfilm and hardcopies total count. There’s a warning icon if some of the microfilms are likely on acetate: a material used for some of the early British Library microfilms, but that degrades, so can’t be digitised off. A numeric code (the title’s ID in the British Library systems) at the far left is hyperlinked to the title’s British Library catalogue record online. You can scroll vertically through the titles.
Branching design to represent title name changes
Customising our design meant that we could communicate important complexities in the data—like title name changes. Press Picker runs off the ‘British and Irish Newspapers’ dataset created by the British Library Contemporary British and Collections Metadata teams. In this dataset, each new publication name is considered a new and separate title. The connections between titles are recorded in free text format under two data fields: ‘preceding title’ and ‘succeeding title’. In order to identify links across the dataset, we used string cleaning (computationally splitting the text data into words and handling punctuation and case) with Regular Expressions to find matching title names. To help distinguish between titles where the name is more generic (eg. Daily News), we only connected records with a matching ‘general area of coverage’ data field.
Creating these linkages in the data meant we could bring together connected titles with a branching design in the visualisation. While we found this linking approach to be successful the vast majority of the time, we made sure the underlying data can be inspected in the interface; hovering over small grey arrow icons above each title’s name reveals the original data as a tooltip (a small text box).

Press Picker could be described as a sparklines design: small graphs, presenting measurements in a simple and highly condensed way. This kind of dense data display is useful for seeing the changing price of stocks, or patient vital signs in clinical data. We’re doing it to overview historic newspaper holdings.
The image below shows the design as it looks embedded in the Jupyter notebook. Titles can be selected using selection boxes on the left. The records can be viewed and a selection can be exported. Because we required a custom design, we created the visualisation in JavaScript using the flexible visualisation library D3. We embedded this JavaScript code in the Python Jupyter notebook. We have written a separate blogpost detailing how to do this.
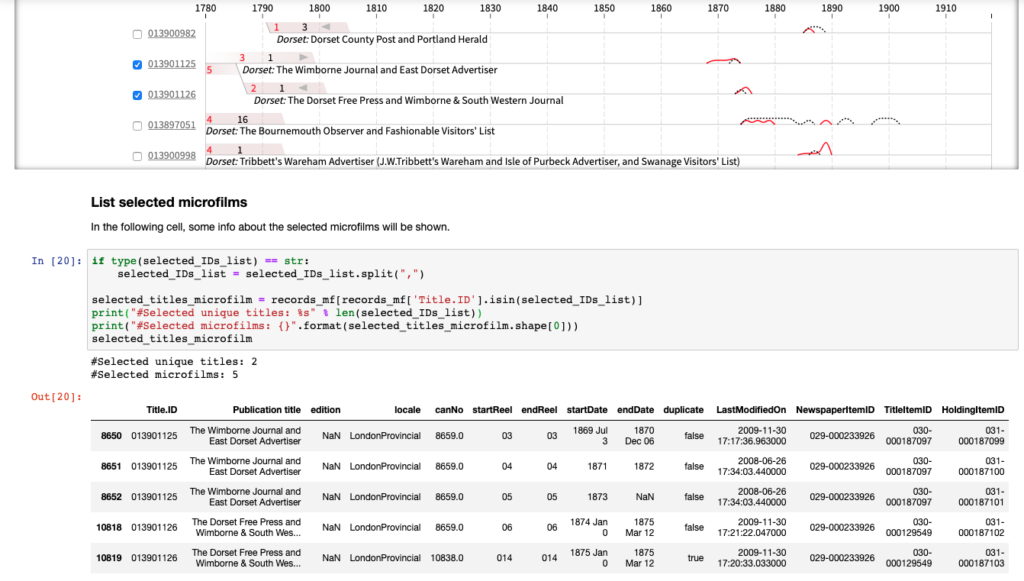
Press Picker is a powerful tool for overviewing the British Library’s newspaper holdings. You can identify titles where a majority of issues are available as good-quality microfilm. You can see those with longer runs, and name changes through time are made clear. Selecting titles was done by a historian on the Living with Machines team, whose period expertise complements what Press Picker supports. Those selections have been progressed to digitisation.
We’re now exploring Press Picker’s potential helping manage newspaper metadata internally at the British Library, and for British Library readers. It may also be of interest to other libraries with significant newspaper holdings. The code isn’t publicly available yet, but we will be sharing it when we’re able to.
Press Picker was developed by Olivia Vane, Kasra Hosseini and Giorgia Tolfo.
Many thanks to Yann Ryan, the British Library Newspapers Collection curatorial team, Heritage Made Digital and the Imaging Studio for their help and guidance.
Dataset credit: ‘British and Irish Newspapers’, 2019, https://bl.iro.bl.uk/work/7da47fac-a759-49e2-a95a-26d49004eba8 , by British Library Contemporary British and British Library Collections Metadata.
Latest posts from us







