Working with Zooniverse’s Caesar system for crowdsourcing workflows
Zooniverse, a hugely popular citizen science platform, has a project builder (called Panoptes) than anyone can use to build a crowdsourcing project. We’ve been using it to create tasks around 19th century newspaper articles, from finding stories about accidents involving machinery, to asking people to define or describe machines mentioned in articles, then building on our initial accidents work to gather more detail about the accidents described.
One of the basic concepts in Zooniverse is that ‘subject sets’ – sets of images, usually – are linked to ‘workflows’, one or more tasks you can do with an image. Tasks are often questions with different choices, but they might also involve drawing on the image or answering survey-style questions.
As our use of Zooniverse for crowdsourcing tasks has grown over time, we’ve found ways to use their caesar tool, designed to help with data aggregation, with our tasks. Earlier this year, we started to look into ways to use the results of one Zooniverse task – e.g. classifying articles – in another task – e.g. adding more detail about articles that met certain criteria. It can be hard to find examples for how to use caesar, so we’re sharing what we’ve done in case it helps others.
We figured out how to move images between tasks based on how they were classified with help from Cam Allen, one of Zooniverse’s awesome developers, who set up the first versions of the rules shown below.
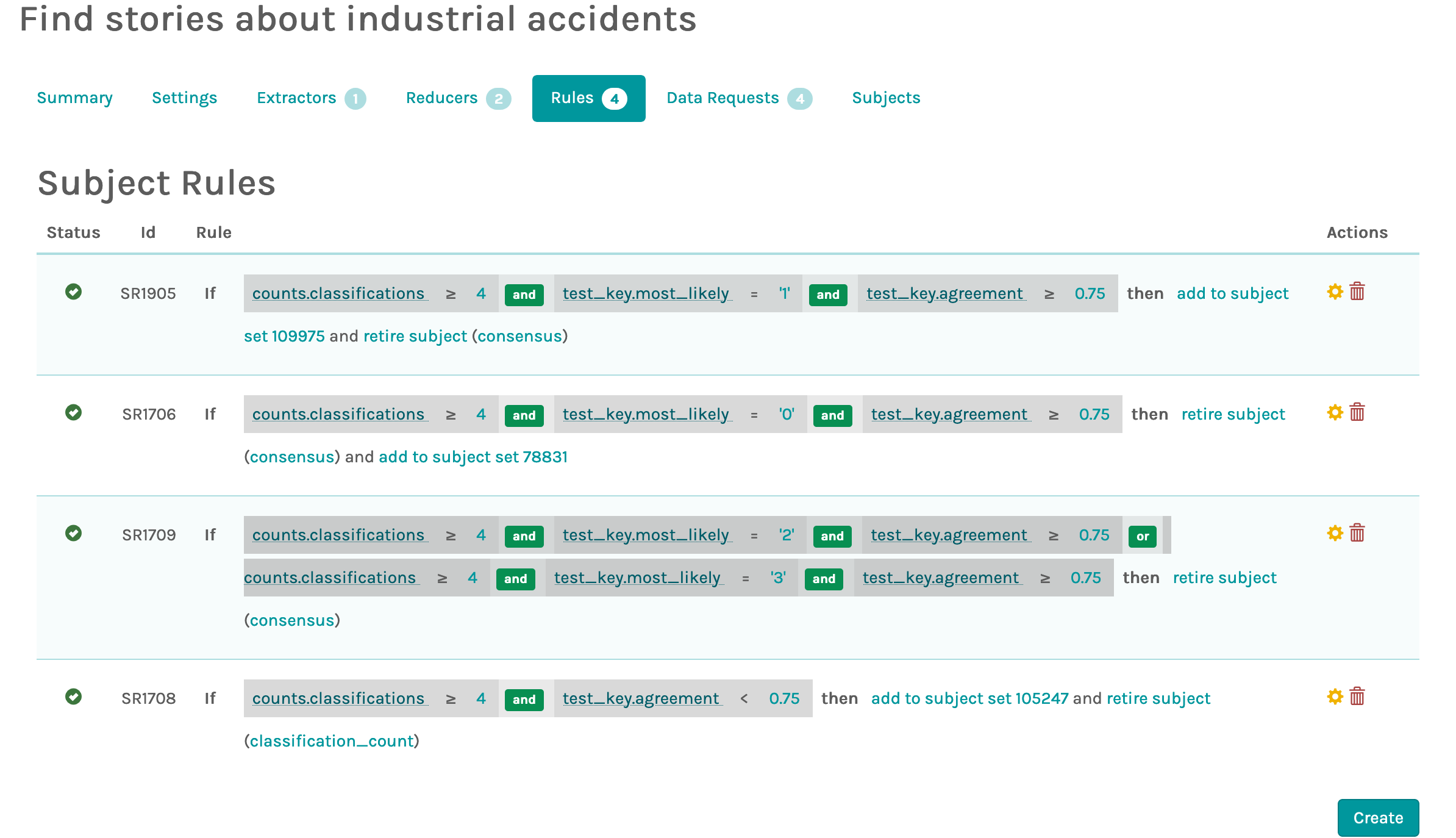
The solution was to copy images that were classified a certain way (e.g. test_key.most_likely ‘0’ etc above, with 0, 1, 2 and 3 representing choices in a question task) into specific folders (subject sets in Zooniverse jargon), then use those folders with the detail tasks. Images that didn’t meet our criteria aren’t copied over. I’ve sketched the overall workflow in an earlier post about our ‘how did machines change accidents?’ task.
Cam also helped us set up smarter ‘retirement’ rules, so that images were retired from a task only after 4 or more volunteers classified it the same way. Without that, images could be retired before there was an agreement on how it should be classified, as long as enough people had classified it. Usually people will agree, but we were seeing some images ‘retire’ before there was majority agreement on how to classify them.

The rules can look a bit obscure – here are two I worked on with Kalle today:
Updated SR1706
["and", ["gte", ["lookup", "counts.classifications", 0], ["const", 4]], ["eq", ["lookup", "test_key.most_likely", "?"], ["const", "0"]], ["gte", ["lookup", "test_key.agreement", 0], ["const", 0.75]]]New SR1905
["and", ["gte", ["lookup", "counts.classifications", 0], ["const", 4]], ["eq", ["lookup", "test_key.most_likely", "?"], ["const", "1"]], ["gte", ["lookup", "test_key.agreement", 0], ["const", 0.75]]]There’s a lot of jargon to get your head around – ‘Extractors are used to take classifications coming out of Panoptes and extract the relevant data needed to calculate a aggregated answer for one task on a subject’, ‘Reducers are functions that take a list of extracts and combines them into aggregated values’ – but caesar can be incredibly useful. The forums can be helpful, and Zooniverse’s own experts can help if you get in touch via email.
Edit to add: Pmason has collected ‘Links to info on Caesar‘ with example ‘retirement’ rules and more.
Latest posts from us







